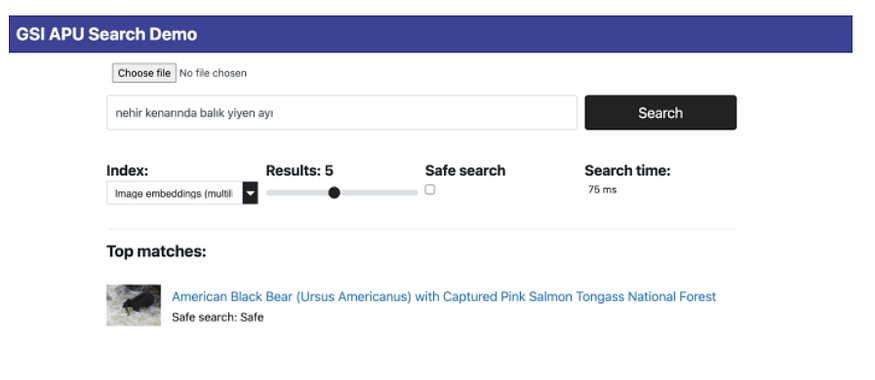
Learn how to install OpenSearch Benchmark, create “workloads,” and benchmark them between computing devices
OpenSearch users often want to know how their searches will perform in various environments, host types, and cluster configurations. OpenSearch Benchmark, a community-driven, open-source fork of Rally, is the ideal tool for that purpose.
OpenSearch-benchmark helps you to reduce infrastructure costs by optimizing OpenSearch resource usage. This tool also enables you to discover performance regressions and improve performance by running periodic benchmarks. Before benchmarking, you should try several other steps to improve performance — a subject I discussed in an earlier article.
In this article, I will lead you through setting up OpenSearch Benchmark and running search performance benchmarking comparing a widely used EC2 instance to a new computing accelerator — the Associative Processing Unit (APU) by Searchium.ai.
Step 1: Install Opensearch-benchmark
We’ll be using an m5.4xlarge (us-west-1) EC2 machine on which I installed OpenSearch and indexed a 9.1 M-sized vector index called laion_text. The index is a subset of the large laion dataset where I converted the text field to a vector representation (using a CLIP model):
Install Python 3.8+, including pip3, git 1.9+, and an appropriate JDK to run OpenSearch. Be sure that JAVA_HOME points to that JDK. Then run the following command:
sudo python3.8 -m pip install opensearch-benchmark
Tip: You might need to install each dependency manually.
sudo apt install python3.8-devsudo apt install python3.8-distutilspython3.8 -m pip install multidict –upgradepython3.8 -m pip install attrs — upgradepython3.8 -m pip install yarl –upgradepython3.8 -m pip install async_timeout –upgradepython3.8 -m pip install aiosignal — upgrade
Run the following to verify that the installation was successful:
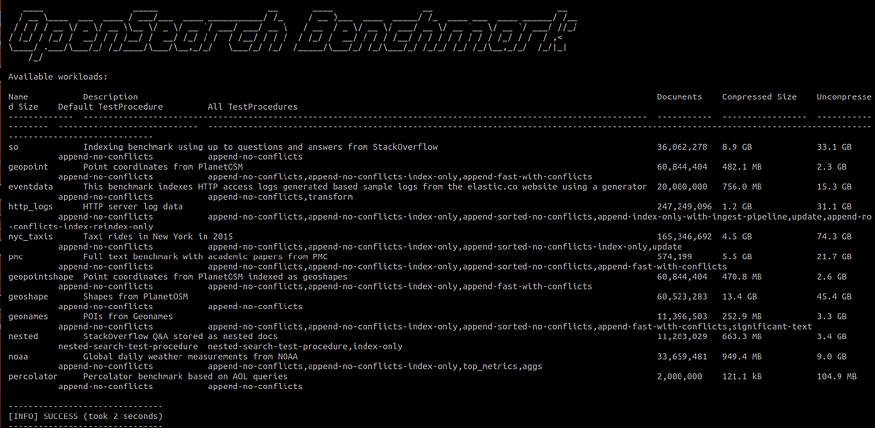
opensearch-benchmark list workloads
You should see the following details:
Step 2: Configure Where You Want Results To Be Saved
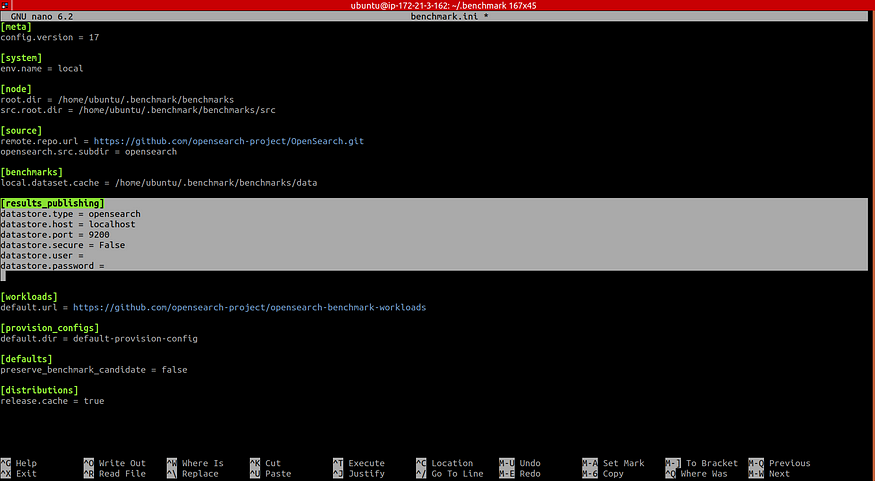
By default, OpenSearch Benchmark reports to “in-memory.” If set to “in-memory,” all metrics will be kept in memory while running the benchmark. If set to “opensearch,” all metrics will be written to a persistent metrics store, and the data will be available for further analysis.
To save the reported results in your OpenSearch cluster, open the opensearch-benchmark.ini file, which can be found in the ~/.benchmark folder and then modify the results publishing section in the highlighted area to write to the OpenSearch cluster:
Step 3: Construct the Search “Workload”
Now that we have OpenSearch Benchmark installed properly, it’s time to start benchmarking!
The plan is to use OpenSearch Benchmark to compare searches between two computing devices. You can use the following method to benchmark and compare any instance you wish. In this example, we will test a commonly used KNN flat search (an ANN example using IVF and HNSW will be covered in my next article) and compare an m5.4xlarge EC2 instance to the APU.
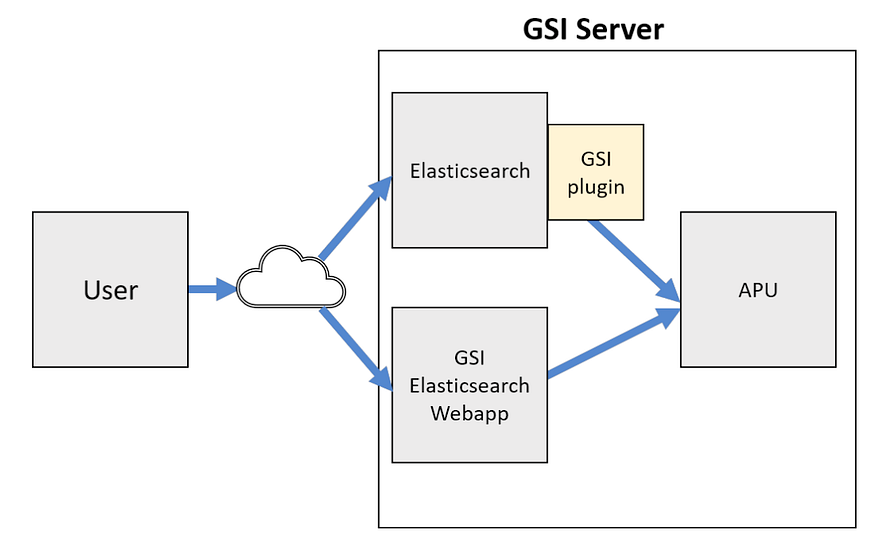
You can access the APU through a plugin downloaded from Searchium.ai’s SaaS platform. You can test the following benchmarking process on your own environment and data. A free trial is available, and registration is simple.
Each test/track in OpenSearch Benchmark is called a “workload.” We will create a workload for searching on the m5.4xlarge, which will act as our baseline. We will also create a workload for searching on the APU on the same EC2, which will act as our contender. Later, we will compare the performance of both workloads.
Let’s start by creating a workload for both the m5.4xlarge (CPU) and the APU using thelaion_text index (make sure you run these commands from within the .benchmark directory):
opensearch-benchmark create-workload --workload=laion_text_cpu --target-hosts=localhost:9200 --indices="laion_text”
opensearch-benchmark create-workload --workload=laion_text_apu --target-hosts=localhost:9200 --indices="laion_text”
Note: If the workloads are saved in a _workloads_ folder in your _home_ folder, you will need to copy them to the _.benchmark/benchmarks/workloads/default_ directory.
Run the opensearch-benchmark list workloads again and note that both laion_text_cpu and laion_text_apu are listed.
Next, we’ll add operations to the test schedule. You can add as many benchmarking tests as you want in this section. Add each test to the schedule in the workload.json file, which can be found in the folder with the index name you wish to benchmark.
In our case, it can be found in the following areas:
./benchmark/benchmarks/workloads/default/laion_text_apu./benchmark/benchmarks/workloads/default/laion_text_cpu
We want to test out our OpenSearch search. Create an operation named “single vector search” (or any other name) and include a query vector. I cut out the vector itself because a 512 dimension vector would be a bit long… Add in the desired query vector and make sure to copy the same vector to the m5.4xlarge (CPU) and APU workload.json files!
Next, add any parameters you want. In this example, I will stick with the default eight clients and 1,000 iterations.
m5.4xlarge (CPU) workload.json:
{
"schedule":[
{
"operation":{
"name":"single-vector-search",
"operation-type":"search",
"body":{
"size":"10",
"query":{
"script_score":{
"query":{
"match_all":{
}
},
"script":{
"source":"knn_score",
"lang":"knn",
"params":{
"field":"vector",
"query_value":[
"INSERT VECTOR HERE"
],
"space_type":"cosinesimil"
}
}
}
}
}
},
"clients":8,
"warmup-iterations":1000,
"iterations":1000,
"target-throughput":100
}
]
}
APU workload.json:
{
"schedule":[
{
"operation":{
"name":"single-vector-search",
"operation-type":"search",
"body":{
"size":"10",
"query":{
"gsi_knn":{
"field":"vector",
"vector":[
"INSERT VECTOR HERE"
],
"topk":"10"
}
}
}
},
"clients":8,
"warmup-iterations":1000,
"iterations":1000,
"target-throughput":100
}
]
}
Step 4: Run our Workloads
It’s time to run our workloads! We are interested in running our search workloads on a running OpenSearch cluster. I added a few parameters to the execute_test command:
Distribution-version — Make sure to add your correct OpenSearch version.
Workload — Our workload name.
Other parameters are available. I added the pipeline, client-options, and on-error, which simplifies the whole process.
Go ahead and run the following commands, which will run our workloads:
opensearch-benchmark execute_test --distribution-version=2.2.0 --workload=laion_text_apu --pipeline=benchmark-only --client-options=verify_certs:false,use_ssl:false --on-error=abort --client-options="timeout:320"
opensearch-benchmark execute_test --distribution-version=2.2.0 --workload=laion_text_cpu --pipeline=benchmark-only --client-options=verify_certs:false,use_ssl:false --on-error=abort --client-options="timeout:320"
And now we wait…
Bonus benchmark: I was interested to see the results on an Arm-based Amazon Graviton2 processor, so I ran the same exact process on an r6g.8xlarge EC2 as well.
Our results should look like the following:
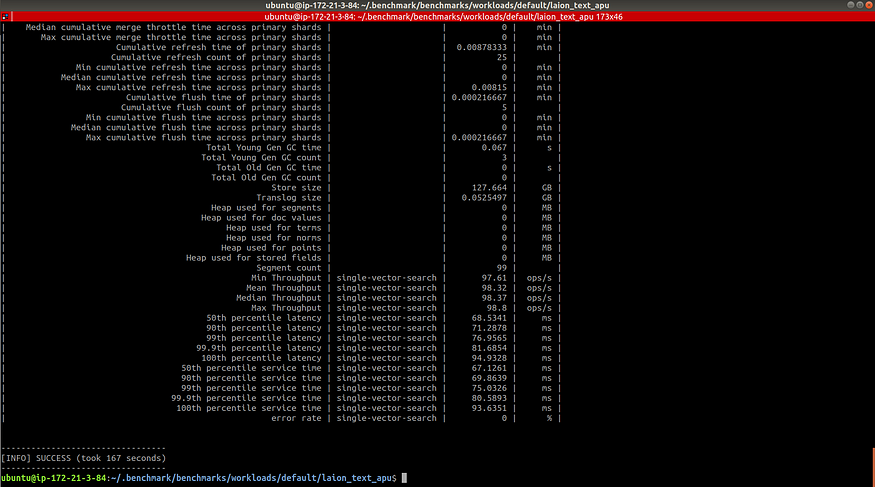
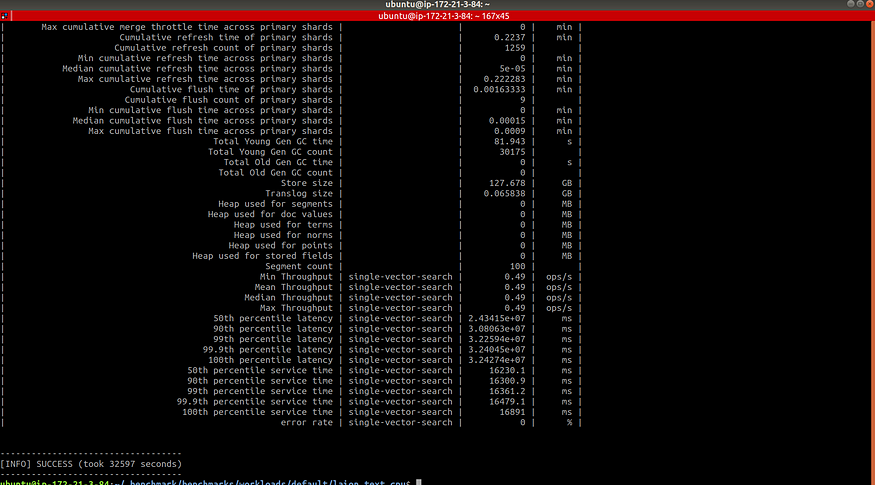
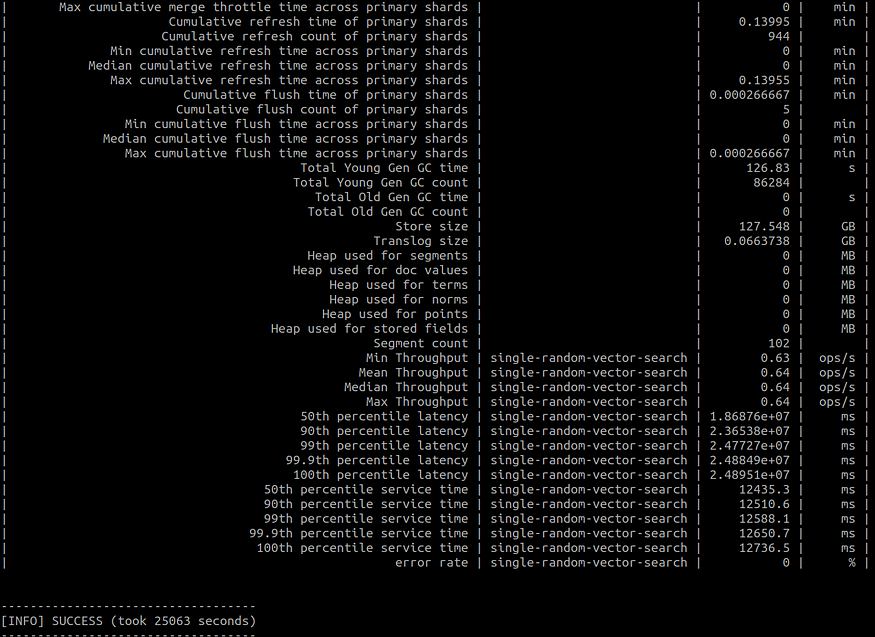
Step 5: Compare our Results
We are finally ready to look at our test results. Drumroll, please… 🥁
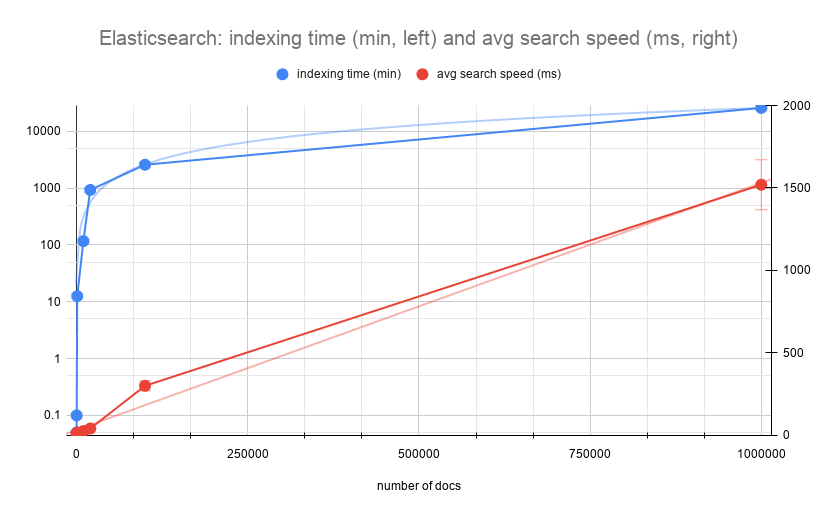
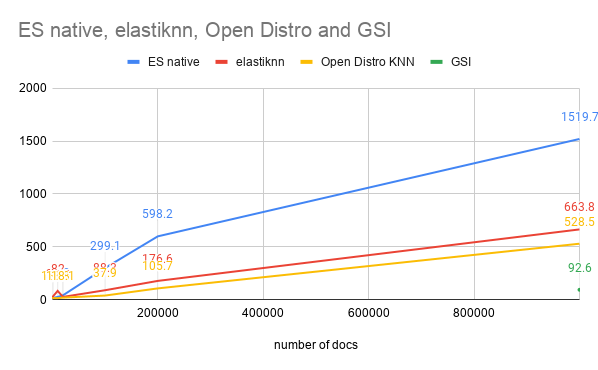
First, we noticed the running times of each workload were different. The m5.4xlarge workload took 9 hours, and the r6g.8xlarge workload took 6.96 hours, while the APU workload took 2.78 minutes. This is because the APU also supports query aggregation, allowing for greater throughput.
Now, we want a more comprehensive comparison between our workloads. OpenSearch Benchmark enables us to generate a CSV file where we can scompare between workloads easily.
First, we will need to find the workload IDs for each case. This can be done by either looking in the OpenSearch benchmark-test-executions index (which was created in step 2) or in the benchmarks folder:
Using the workloads IDs, run the following command to compare two workloads and display the output in a CSV file:
opensearch-benchmark compare --results-format=csv --show-in-results=search --results-file=data.csv --baseline=ecb4af7a-d53c-4ac3-9985-b5de45daea0d --contender=b714b13a-af8e-4103-a4c6-558242b8fe6a
Here’s a short summary comparing three of our workload results:
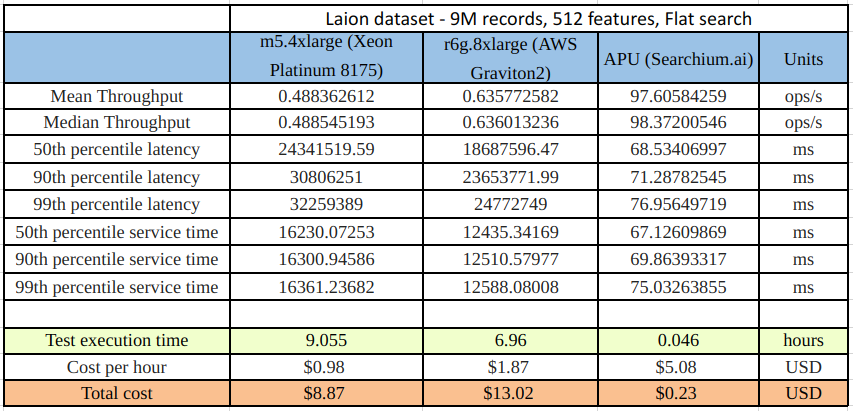
A brief explanation of the results in the table:
Throughput: The number of operations that OpenSearch can perform within a certain period, usually per second.
Latency: The time between submitting a request and receiving the complete response. It also includes wait time, i.e., the time the request spends waiting until it is ready to be serviced by OpenSearch.
Service time: The time between sending a request and receiving the corresponding response. This metric can easily be confused with latency but does not include waiting time. This is what most load testing tools incorrectly refer to as “latency.”
Test execution time: The total runtime from starting the workload until completion.
Conclusion
When looking at our results, we can see that the service time for the APU workload was 197 times faster than the m5.4xlarge workload and 151 times faster then the r6g.8xlarge. From a cost perspective, running the same workload on the APU costs $0.23 as opposed to $8.87 on the m5.4xlarge (38 times less expensive) and $13.02 on the r6g.8xlarge (56 times less expensive), and we got our search results almost 9 hours (m5.4xlarge) and 6.91 hours (r6g.8xlarge) earlier.
Now, imagine the magnitude of these benefits when scaling to even larger datasets, which is likely to be the case in our data-driven, fast-paced world.
I hope this helped you understand more about the power of OpenSearch’s benchmarking tool and how you can use it to benchmark your search performance.
For more information about Searchium.ai’s plugin and the APU, please visit www.searchium.ai. They even offer a free trial!